技術資料
Feel&Think
第8回 強化学習
前回の「深層学習(言語系)」では、言語系の深層学習に使用されるアリゴリズムについて歴史的な背景を踏まえて説明しました。
今回は、強化学習(Reinforcement Learning, RL)のアルゴリズムについて歴史的な背景を踏まえて詳細に説明します。
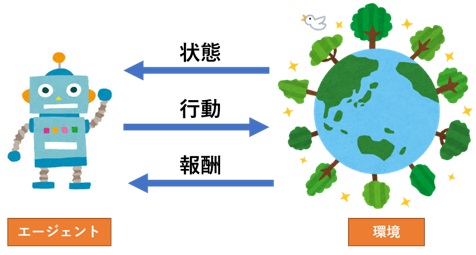
■初期の探求(1950年代 – 1980年代)
RLの初期の探求は、1950年代から1980年代にかけての科学と技術の進展により形成されました。この時期は、RLの基礎理論が確立され、初期のアルゴリズムが開発された重要な時代です。
1950年代のRLは、サイバネティクス1)と早期のコンピューター科学の研究に大きく影響を受けました。ノーバート・ウィーナーはサイバネティクスの概念を導入し、機械と生物系の間の情報フィードバックループについての理論を提唱しました。これは、後のRLアルゴリズムにおける報酬に基づく学習プロセスの基礎を形成しました。
1960年代には、行動心理学、特にB.F.スキナーのオペラント条件付け2)がRLの理論的枠組みに影響を与えました。スキナーは、報酬や罰によって行動が形成されるという概念を提供し、これがRLにおける「報酬に基づく学習」という核心的な概念に直接的な影響を与えました。また、この時期の心理学者たちは、動物の学習過程をモデル化し、報酬に基づく学習理論を実験的に検証しました。
1970年代には、コンピューター技術の進歩がRLの発展に貢献しました。コンピューターの計算能力の向上は、より複雑なアルゴリズムの開発を可能にしました。この時代の研究者たちは、環境とのインタラクションに基づいて最適な行動を学習する初期のRLアルゴリズムの開発に取り組みました。
1980年代は、RLの理論的枠組みとアルゴリズム開発の両方において重要な進展が見られました。リチャード・サットンとアンドリュー・バルトは、時間差分学習(TD学習)を導入し、RLの報酬予測の重要な手法として確立しました。TD学習は、連続的な試行錯誤を通じて最適な行動戦略を学習するという、RLの基本的なアイデアを体現しています。
■初発展期(1990年代)
1990年代はRLの発展にとって非常に重要な時代でした。この時期には、理論的な進歩と実用的な応用が大きく進み、RLの将来の方向性を大きく定めることになりました。
この時代の重要な進歩には、以下のようなものがあります。
1992年にクリス・ワトキンスによって発表されたQ学習アルゴリズムは、RL分野における重要な進展を表しています。このアルゴリズムは、エージェントが特定の状態で最適な行動を選択し、長期的な報酬を最大化する方法を学習することに焦点を当てています。また、Q学習はオフポリシー学習の概念を導入しました。これは、エージェントが現在の政策に従わない行動からも学習する能力を意味し、RLアルゴリズムの効率と汎用性の向上に貢献しました。この革新的なアプローチにより、Q学習はRLの理論と実践の発展において大きな役割を果たしています。
1990年代後半には、方策勾配法がRLの研究で注目され始めました。これは、直接的な方策(行動の確率分布)を最適化する手法で、特に連続的な行動空間での問題に適しています。
ジェラルド・テサウロによって開発されたバックギャモンプレイヤーは、RLが実世界の複雑なタスクに対処できることを示す画期的な例でした。このシステムは、世界クラスのプレイヤーと同等、あるいはそれ以上のパフォーマンスを発揮し、RLの実用性を広く示しました。バックギャモンでの成功を受けて、RLの応用はチェスやポーカーなど他のゲームにも拡大されました。これらの応用は、RLが様々な戦略的意思決定問題に適応できることを証明し、RLの応用範囲が広がる重要なきっかけとなりました。3)

■現代への発展(2000年代 – 現在)
2000年代から現在にかけてのRLの発展は、技術革新と応用の拡大によって特徴づけられます。この時期、RLはディープラーニングとの統合を遂げ、多様な領域での実用的応用が実現しました。
RLにディープラーニング、特にディープニューラルネットワークを組み込むことで、ディープ強化学習が誕生しました。この新しいアプローチにより、RLは以前には取り組みが困難だった複雑な問題を解決する能力を獲得しました。
また、DeepMind5)によって開発されたAlphaGo(第3回の【coffee break】にて記載)の成功は、ディープ強化学習の潜在能力を世界に示しました。AlphaGoはプロの囲碁プレイヤーに勝利し、RLの分野における新しい時代の幕開けを告げました。
新しいアルゴリズムの開発としては、例えば、DQN(Deep Q-Network)やA3C(Asynchronous Advantage Actor-Critic)などが挙げられ、RLの効率と効果を大幅に向上させました。
■今後の展望
現在のRLは特定のタスクや環境に特化していますが、今後は異なるタスクや環境に対応可能な汎用的なモデルの開発が目指されます。これにより、RLアルゴリズムは様々な状況に迅速に適応できるようになることが期待されます。
また、RLシステムが新しい環境やタスクに迅速に適応するためのメタ学習(学習方法の学習)が注目されています。これは、RLアルゴリズムの柔軟性と応用範囲を拡大する重要な要素です。
さらに、RLは、気候変動、交通管理、災害対応など、実世界の複雑な問題に対する解決策を提供するために用いられることが期待されています。
強化学習の未来は、テクノロジーの進化とともに形成されていきます。これには、AI技術の進歩だけでなく、社会的、倫理的な側面への配慮も含まれます。RLの進化は、私たちの日常生活、ビジネス、科学研究における意思決定に影響を与え、新たな問題解決のアプローチを提供する可能性を秘めています。
さらに、Transformerに基づいた大規模言語モデル(LLM)が様々な能力を示すことが明らかになり、強化学習において制御していたロボットの分野においてもその手法を適用し、両者の融合がなされています。
今回は、歴史的な背景をメインに説明しました。今回十分に説明できていない重要なキーワードとして以下のものがあります。
- マルコフ決定過程
- ベルマン方程式
- 動的計画法
- モンテカルロ法
- TD法
- ニューラルネットワークとQ学習
- DQN
- 方策勾配法
これらのキーワードについては、別の機会に改めて詳しく説明したいと思います。
第9回は、地層科学分野における事例について紹介していきます。
参考資料
1)サイバネティクス「11月26日サイバネティクスの提唱者ノーバート・ウィートナー誕生(1894年)」
2)オペラント条件づけ「ウィキペディア(Wikipedia):フリー百科事典」最終更新2023年7月12日(水)11:07
3)ゲームAIの進化と歴史(2019年8月19日)
4)バックギャモン「ウィキペディア(Wikipedia):フリー百科事典」最終更新2023年11月14日(火)09:38
5)DeepMind
※上記コラム内のWebサイトの最終参照日は、2023年11月