技術資料
Feel&Think
第3回 機械学習とAI
前回の「AIの歴史」では、AIの概念をはじめ、数回にわたる「ブーム」と「冬の時代」について代表的なシステムを示し説明しました。また、最新の画像作成AI「Midjourney」について作成された画像の高品質性について触れました。
今回の第三回では、機械学習とAIという観点から説明します。この二つは下図(図-1)のような関係にあり、機械学習は、AIの一部に含まれます。

機械学習とは、コンピューターにデータを入力し、特定のアリゴリズムに基づいて分析することができる手法であり、使用されるアルゴリズムとしては、古くから存在し、これまでもいろいろな分野で適用されてきました。
機械学習には代表的な手法として、「教師あり学習(Supervised learning)」、「教師なし学習(Unsupervised learning)」、「強化学習(Reinforcement learning)」の三種類があります。
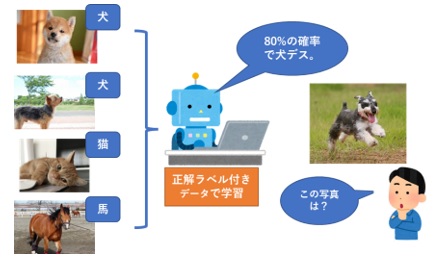
■教師あり学習(Supervised learning)
教師あり学習とは、コンピューターに正解のラベルがついたデータを学習させる手法であり、現在、世の中でAIと言われているほとんどがこの手法を用いたものです。この手法のタスクには、学習されたデータから犬の画像を犬と判断することができるような「分類(Classification)」タスクや、未来の商品の売り上げを予測することができるような「回帰(Regression)」タスクがあります。
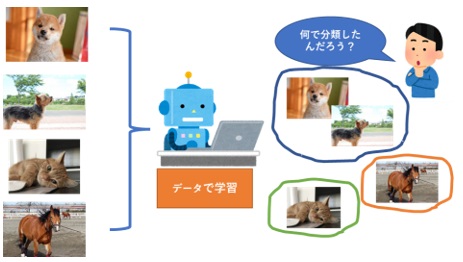
■教師なし学習(Unsupervised learning)
教師なし学習とは、文字通り教師あり学習とは異なり、正解のラベルがないため、あるデータ群を類似した特徴から分類する「クラスタリング」タスクや、データをより少ない次元の情報に落とし込むことができる「次元圧縮」タスクなどがあります。
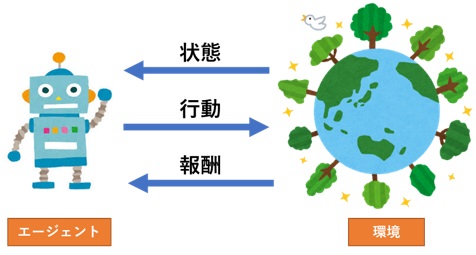
■強化学習(Reinforcement learning)
強化学習とは、AlphaGoでも使用されている手法であり、人がルールを作成することはせず、コンピューター自身に試行錯誤させることで、「価値を最大化するような行動」を学習するものです。図4のようにエージェントは、環境から状態を取得し、その状態に対して最適な行動をおこすことで、報酬をもらいます。前述のように、エージェントは、その報酬が最大になるような行動を学習することになります。

~Break~
AlphaGoは、Google DeepMindよって開発された囲碁プログラムであり、2015年10月に、人間のプロ囲碁棋士にハンディ無しで勝利した初のプログラムです。AlphaGoの仕組み自体は、以前の人間が設定した評価経験則に従うのではなく、既存の棋譜データをもとに、自分自身との対戦を数千万回行うことによって自分自身を強化していきます。ここで、使用した探索アルゴリズムをモンテカルロ木探索といいAlphaGoの特徴の一つです。
AlphaGoはその後もバージョンアップを続け、最終的には、2017年5月に「人類最強」とうたわれた柯潔※1と対戦し、3戦全勝という圧倒的な強さを見せつけました。
その5か月後には、既存のAlphaGoをはるかに上回る強さのバージョンが開発されました。その名前は、AlphaGo Zeroといい、このバージョンは、これまで人間が用意した棋譜での対戦を行わず、自分自身との対戦だけで強化されていきました。
その後、AlphaGo Zeroは、Alpha Zeroとなり、囲碁だけでなく、チェスや将棋といった他のボードゲームでも同様の強さを証明しました。
※1:中国の囲碁棋士 か けつ氏のこと

第4回は、機械学習全般について説明します。
参考資料
・AlphaGo「ウィキペディア (Wikipedia): フリー百科事典」最終更新 2023年1月28日 (土) 15:25
・AlphaGoのしくみ(slideshareより)
※上記コラム内のWebサイトの最終参照日は2023年5月