技術資料
Feel&Think
第7回 深層学習(言語系)
前回の「深層学習(画像系)」では、画像系の深層学習に使用されるアリゴリズムについて説明しました。現在もあらたにモデルが提案されるなど、個々のアルゴリズムは日々進化を続けています。
今回は、深層学習(言語系)のアルゴリズムについて歴史的な背景を踏まえて詳細に説明します。後半部分は、第4回「機械学習(教師あり学習)」の最後に説明した内容と一部重複するかもしれませんが再度説明します。
■前史
1950 年代から1960 年代初めにかけて、コンピューター科学の誕生とともに、人間の言語を機械が理解し、処理できるようにするというアイデアが浮上しました。この時代の研究者たちは、言語の構造や意味を正確に表現するための明確なルールやアルゴリズムの定義に取り組んでいました。
その主な定義は、文法規則の定義や、意味表現の定義などです。ただし、限定的な適用範囲や高いメンテナンスコストが課題となりました。
代表的なプロジェクトにELIZAやSHRDLUがありました。特に、MITでジョセフ・ワイゼンバウムによって開発された初期の自然言語処理プログラムELAZAは、ユーザーが打ち込んだ言葉やフレーズを取り上げて、質問や再表現を返すことで対話を継続するというもので、実際に人間のセラピストのように思えるほど印象的だったため、多くの人々がELIZAとの対話に深く引き込まれたことが知られています。
しかし、このルールベースのアプローチは、初期の成功を収める一方で、実際の言語の複雑さと多様性を捉えきれないという限界に直面しました。特に、アンビギティ(曖昧性)や言語の進化、文化的・地域的なニュアンスを取り扱うのが困難でした。これらの課題に対するため、研究者たちは新しいアプローチ、特にデータ駆動の方法に目を向けるようになりました。
■統計的方法の導入
1980年代後半から1990年代にかけて、コンピューターの計算能力の向上やデータの容易な収集が可能となったことで、データ駆動型のアプローチが可能になりました。このときから、人によるルール作成よりも、大量のテキストデータから自動的に言語のパターンを学習する統計的手法の導入が進められました。
その主な手法に、隠れマルコフモデル(HMM: Hidden Markov Model)、統計的機械翻訳(SMT: Statistical Base Machine Translation)、N-gramモデルがあります。
HMMは、観測データの系列から隠れた状態の系列を予測する確率モデルで、品詞タグ付けや音声認識のタスクで広く用いられ、STMは、対訳コーパスから翻訳モデルを学習し、新しい文章を翻訳する際に使用されました。N-gramモデルにおいては、テキストの単語の出現確率を、前のN-1個の単語に基づいてモデル化する手法で、特に音声認識や文字予測のタスクで利用されました。
これらは、大量のデータから言語のパターンを自動的に学習することで、多様な表現やニュアンスにも対応可能なモデルが作成され、また統計的手法の導入により、機械翻訳、音声認識、情報検索などの多様なNLPタスクに取り組むことが可能となりました。
しかし、この統計的手法は、多くのNLP(自然言語処理: natural language processing)タスクで高い性能を達成しましたが、深層的な言語の理解や文脈の捉え方には限界がありました。また、高品質な対訳コーパスや大量のアノテーションが必要であるという課題もありました。
■初期のニューラルネットワーク
2000年代初頭、統計的手法が多くのNLPタスクにおいて一定の成功を収めていましたが、言語の複雑な関係やニュアンスを捉えることに限界を感じるようになりました。この時期、ニューラルネットワークというディープラーニングのアプローチが再び注目を浴びるようになってきました。
その主な手法は、word2vec、GloVe(Global Vectors for Word Representation)などがあります。
word2vecは、2013年にGoogleのMikolovらによって発表され、ニューラルネットワークを使用して大量のテキストデータから単語のベクトル表現を学習する手法で、特にSkip-GramやCBOW(Continuous Bag of Words)というモデルが提案され、単語の意味的・文法的関係を高次元空間で捉えることができるようになりました。最も有名な例は、
KING – MAN + WOMAN ≈ QUEEN
であり、この計算は、KINGのベクトルからMANを引き、WOMANのベクトルを足すと、結果として得られるベクトルがQUEENのベクトルに非常に近いことを示しています。同様の例として、以下の例があります。
TOKYO – JAPAN + FRANCE ≈ PARIS
GloVeは、2014年にStanford UniversityのPenningtonらによって提案され、共起行列に基づいて単語のベクトル表現を学習する手法です。この手法では、大量のテキストデータの統計情報を効果的に活用して、単語間の意味的関係を反映したベクトルを生成することができるようになりました。
ただし、この初期のニューラルネットワークと単語埋め込みは非常に効果的でしたが、文全体の文脈や長い依存関係を捉えるのは難しく、後の発展への土台となりました。
■RNNとLSTM
2010年代初頭までに、ニューラルネットワークと単語埋め込みがNLPの分野での成功を収めていました。しかし、文中の単語やフレーズが持つ順序や文脈、特に長い依存関係を効果的にモデル化する手法が求められていました。
その主な手法として、RNN(Recurrent Neural Network: 再帰的ニューラルネットワーク)とLSTM(Long Short-Term Memory:長短時系列メモリ)があります。
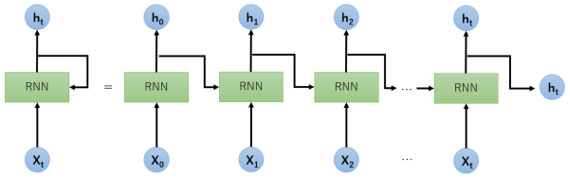
RNN(図1)の基本的な概念は、過去の情報を隠れ層の状態として持ち越し、系列データの各時点での入力とともにこれを更新するニューラルネットワークです。しかし、長い系列を扱う際に勾配消失や勾配爆発という問題を抱えており、長い依存関係を学習することが難しいという課題がありました。一方、LSTMは、RNNの派生形として1997年にHochreiterとSchmidhuberによって提案されました。基本的な概念は、「ゲート」と呼ばれる構造を持ち、情報の流れを調節することで、長い系列の依存関係も効果的にとらえることができます。
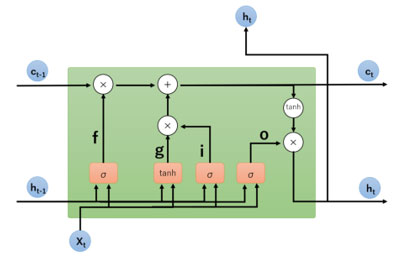
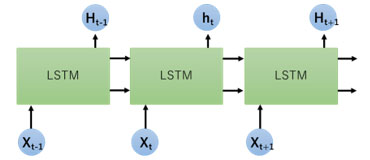
LSTM(図2、図3)の特徴は、入力ゲート(i)、忘却ゲート(f)、出力ゲート(o)の3つのゲートを持ち、これにより不要な情報の削除や必要な情報の保持(g)、出力を適切に制御することができます。いずれのモデルも機械翻訳、文章生成、音声認識、動画解析などのタスクで広く用いられています。
LSTMやその派生形であるGRU(Gated Recurrent Unit)は、NLPだけでなく、多くの系列データを扱うタスク全般で高い性能を発揮しています。これらの成功により、深層学習を用いた系列データのモデル化が一般的となりました。
■AttentionメカニズムとTransformer
RNNやLSTMは系列データのモデル化において一定の成功を収めていましたが、特に長いテキストの変換や翻訳の際に、すべての情報を固定長の状態ベクトルに圧縮するという限界が明らかになってきました。そのため、各単語やフレーズが持つ情報をより直接的に取り扱う新たな手法が求められました。
ある系列を入力として受け取り、別の系列を出力する深層学習モデルのアーキテクチャであるseq2seqが提案されました。これは、エンコーダとデコーダの2つの部分からなり、エンコーダは入力系列を固定長のベクトルに変換し、デコーダはエンコーダが生成した固定長ベクトルを初期状態として、目的の系列を生成します。しかし、このアーキテクチャには、入力系列全体を一つの固定長のベクトルにエンコードするという問題がありました。
そこで考えられたのがAttentionメカニズムです。これは、ある単語を考慮する際に、関連するほかの単語やフレーズの情報を動的に参照する仕組み、具体的には、クリエ、キー、バリューの3つの要素を用いて、入力データのどの部分「注目」すべきかの重みを計算します。この特徴として、例えば、翻訳タスクにおいて、対応する単語やフレーズ間の関係性を直接的にモデル化することが可能となり、より質の高い翻訳結果を得ることができるようになりました。
そして、すべての処理がAttentionメカニズムに基づいて作成されたのが、「Attention is All You Need(2017年論文)」で提案されたTransformerという新しいアーキテクチャです。Transformerは、マルチヘッドAttentionという概念を導入し、複数のAttention層を同時に適用することで、異なる規模の関係性を同時に捉えることができるようになり、従来のRNNやLSTMに代わるものとなりました。ちなみに前出の論文では、位置情報を考慮するPosition Encodingという技術も導入されています。
これらの技術は、BERT、GPT、T5など、多くの派生モデルやアーキテクチャがTransformerをベースに開発され、NLPの分野に革命をもたらしました。
■BERTと事前学習モデル
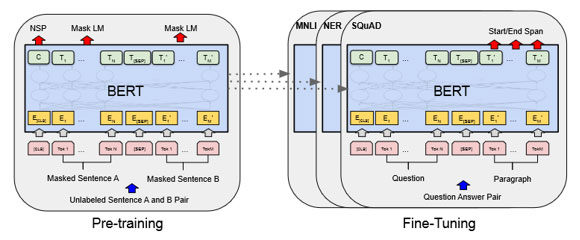
Transformerアーキテクチャの成功を受けて、その能力を活用して汎用的なモデルを作成し、多くのNLPタスクに適用するというアイデアが生まれました。
その代表的なものにBERT (Bidirectional Encoder Representations from Transformers)(図4)があります。これは、Transformerアーキテクチャをベースにした事前学習モデルで、文章中の一部の単語をマスクしてその単語を予測するというタスクで大量のテキストデータを使用してモデルを学習します。また、このモデルは、文章の情報を一方向からではなく、双方向の情報を同時に考慮することができるため、文章の文脈をより正確に理解することができるようになりました。さらに、2段階の学習フェーズ(①大量のテキストデータを用いてモデルを事前学習する ②特定のNLPタスクのデータを用いてモデルをファインチューニングする)で行うことが特徴です。
■モデルの大規模化と転移学習
2020年以降は、GPUやTPUといった専用のハードウェアの進化と並行して、ニューラルネットワークの学習に必要な計算能力も大幅に向上しました。これにより、以前は考えられなかったほどの大規模なモデル学習が現実的になりました。また、インターネットの普及とデジタルデータの急増により、学習に利用できるデータ量も増加し、大量のデータを学習ことができるようになり、モデルの大規模化が実現可能になりました。
その代表的なモデルにGPT-3があり、GPT(Generative Pre-trained Transformer)シリーズは、OpenAIによって提案されたモデルでTransformerのデコーダ部分のみを使ったモデルになります。このGPT-3は、1750億のパラメータを持つ大規模なモデルであり、文章を生成するだけでなく、翻訳、要約、質問応答などの多様なタスクを一つのモデルで行うことができます。
2023年3月にChatGPTがOpenAIから一般に公開され、GPT-4のモデルも使用することが可能になりました。数兆のパラメータを持つといわれ、その性能は、GPT-3を遥かにしのぐ性能を持っています。2023年10月にはGPT-4vが公開され、「目や耳を持った」とSNS等で大変話題になっています(図5)。

しかし、OpenAIだけではなくオープンソースにおいてもLLM(Large Language Model)の開発がすすめられ一部GPT-4を上回る性能を持つLLMも現れていて、今後も目が離せません。
■多言語と低リソース言語への対応
世界には数千の言語が存在しており、それぞれに固有の文化や情報が詰まっています。そのなかでも、低リソース言語は、十分な学習データやアノテーションが存在しない場合が多いため、通常の学習手法では、十分な性能を達成するのが難しい状況です。そのため、現在は、国産LLMの開発が盛んにおこなわれています。
一方、mBERTやXLMのように、複数の言語のテキストデータを同時に学習し、多言語に対応した共通の埋め込み空間を生成し、1つのモデルで複数の言語を処理することが可能なモデルも作成されています。
■今後の展望
一般的なLLMを特定のタスクや業界に特化させるためのファインチューニングが行われていくでしょう。実際に、医療、法律、金融などの分野に特化したモデルの作成がされているようです。土木の分野においても、作成する必要があるかもしれません。
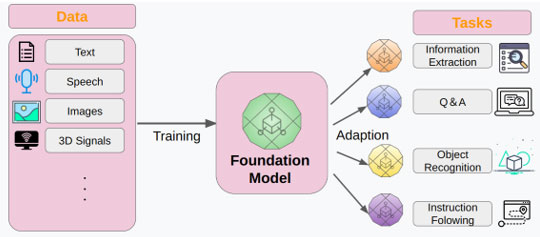
また、今回は、LLMとして紹介しましたが、本来、GPT-3以降は、基盤モデル(Foundation Model)と呼ばれています。基盤モデルとは、大規模なデータを用いて訓練され、様々なタスクに適応(ファインチューニング)できるモデルのことを指します。これらについての詳細は、また別の機会に説明したいと思います。
第8回は、強化学習について説明していきます。
参考資料
1)プリプリントタイトル「BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding」
2)OpenAIサイト
3)プリプリントタイトル「On the Opportunities and Risks of Foundation Models」
※上記コラム内のWebサイトの最終参照日は2023年10月