技術資料
Feel&Think
第6回 深層学習(画像系)
前回の「機械学習(教師無し学習)」では、教師なし学習に使用されるアリゴリズムについて説明しました。実際にコードを実行することでより理解が深まると思います。今回の第6回では、深層学習(画像系)のアルゴリズムについて詳細に説明します。
まず、深層学習(Deep Learning)とは、機械学習の一部として、複雑なパターンを学習するために多数の隠れ層を持つニューラルネットワークを使用する手法のことを指します。
第1回の「AIとは」で紹介したように、深層学習は、2012年のILSVRC(ImageNet Large Scale Visual Recognition Challenge)という画像認識の精度を競うコンペで、トロント大学のジェフリー・ヒントン率いるチームが使用し、優勝したことで有名になりました。その時に使用されたネットワークが畳み込みニューラルネットワーク(Convolutional Neural Network : CNN)の一種であるAlexNetでした。
AlexNetのような画像を使用した深層学習は、畳み込みニューラルネットワーク(CNN)の登場とその派生形態を中心に急速に発展してきました。以下に、画像処理における深層学習の発展の流れと主要な技術やモデルを時系列順に確認していきましょう。
■基本的なCNN(LeNetなど)
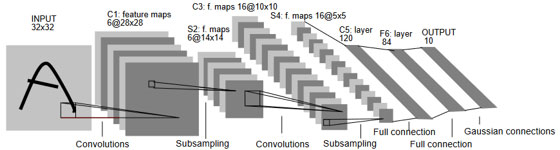
LeNet(図1)は1990年代にYann LeCunらによって提案された初期の畳み込みニューラルネットワーク(CNN)の一つで、このモデルは、特に手書き数字の認識タスクにおいて、その性能を証明しました。 LeNetのアーキテクチャは、畳み込み層、サブサンプリング層、そして全結合層から成り立っています。畳み込み層は、入力画像上をスライドする小さなフィルタを使用して、画像の局所的な特徴を捉えます。サブサンプリング層は、特徴マップのサイズを小さくして計算量を削減し、同時に位置の微小な変化に対するロバスト性を高めます。全結合層は、これらの特徴を組み合わせて、最終的な出力や分類を行います。
■深いCNNの登場(AlexNet, VGGなど)
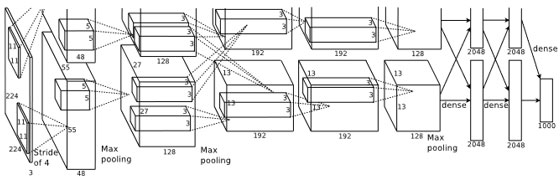
2010年代初頭、大規模なデータセット(ImageNet)での競技が開始されました。この競技は、数百万枚の画像を含むImageNetデータセットにおいて、最も高い精度で画像の分類を行うモデルを競い合わせるものでした。それとは別の大きな変化でもあるGPUの普及とともに、以前よりもはるかに深く、より大規模なネットワークが提案されるようになりました。
AlexNet(図 2)は、それまでのモデルよりもはるかに深く、8層からなるネットワークを持ち、ReLU活性化関数、ドロップアウト、およびデータ拡張などの新しい技術を採用していました。この成功に続き、さらに深いネットワークが提案されるようになりました。例えば、VGGはその名前の通り、Visual Geometry Groupによって提案され、16層や19層といった非常に深いアーキテクチャを持っていました。
■新しい構造の提案(GoogLeNet, ResNetなど)
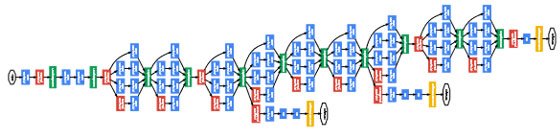
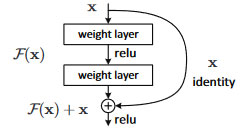
2010年代中盤以降、ディープラーニングの分野は、基本的な深いCNNのアーキテクチャを超えて、さまざまな革新的なネットワーク構造が提案されるようになりました。
GoogLeNet(図 3)においては、異なるスケールの空間情報を同時に捉えるようにしたInceptionモジュールにより、複数の畳み込み操作を同時に行い、その結果を統合することで、多様な特徴を同時に抽出することができました。
一方ResNetでは、勾配の消失/爆発の緩和が目的である残差接続(Residual Connection)(図 4)が提案されました。これは、層の入力をその出力に直接加算するというシンプルな操作であり、これによって勾配がネットワークを通じて効果的に伝播されることが可能となりました。
■転移学習(Transfer Learning)の普及
ImageNetのような大規模なデータセットで学習されたモデルは、数百万枚の画像から得られる多様な特徴を捉える能力を持っています。この学習済みモデルの初期層は、エッジやテクスチャなどの一般的な視覚特徴を捉えることが多く、これらは多くのタスクに共通して有用です。したがって、この学習済みモデルを新しいタスクの基盤として利用し、最後の層だけを新しいタスクのデータに合わせて再学習(微調整: Fine-tuning)することで、新しいタスクでも驚異的な性能を達成することができるようになりました。
転移学習の普及は、ディープラーニングの応用範囲を大きく広げ、医療、衛星画像解析、アート、小規模プロジェクトなど、さまざまな分野での実用化を加速させました。
■アーキテクチャサーチ(Neural Architecture Search, NAS)
従来、ニューラルネットワークのアーキテクチャは、研究者の経験や直感に基づいて設計されていました。しかし、NASのアプローチは、このアーキテクチャの設計プロセスを自動化し、最適なモデル構造をデータ駆動的に探索することを目指しています。
NASの利点は、特定のタスクやデータセットに特化した効率的なモデルを発見できる点にあります。また、NASは、人間のバイアスから解放され、未知の新しいアーキテクチャの組み合わせを試すことができるため、従来の手法では発見できなかったモデル構造を見つけることが期待されます。
■軽量モデルの登場(MobileNet, EfficientNetなど)
エッジデバイスやモバイルデバイスでの実行を目的とした軽量なモデルが設計され、計算リソースが制限されている環境でも高い性能を達成することができました。
MobileNetやEfficientNetは、この動向を象徴するモデルの一部です。例えば、MobileNetは、深さ方向の畳み込みと点方向の畳み込みを組み合わせることで、計算量を大幅に削減しながらも高い性能を維持しています。EfficientNetは、モデルの幅、深さ、画像の解像度のバランスを動的に調整することで、効率的に性能を向上させるアプローチを取っています。
さらに、これらのモデルを最適化するための技術として、量子化(Quantization)、プルーニング(Pruning)、知識蒸留(Knowledge Distillation)などがあります。量子化は、モデルのパラメータの精度を低減することで、モデルのサイズを削減し、実行速度を向上させます。プルーニングは、モデルの不要なパラメータや接続を削除することで、計算量を減少させます。知識蒸留は、大きなモデルの知識を小さなモデルに伝達する手法で、大きなモデルの性能を、小さなモデルで実現することを目指しています。
■セマンティックセグメンテーションや物体検出
セマンティックセグメンテーションや物体検出は、ディープラーニングの進化とともに急速に進展してきた分野です。これらのタスクは、画像内の物体の正確な位置や境界、種類を同定することを目的としており、自動運転車、医療画像解析、監視カメラのアプリケーションなどに不可欠な技術となっています。
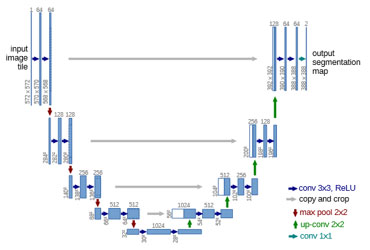
U-Net(図 5)は、医療画像のセグメンテーションを目的に開発されたモデルで、その特徴的なU字型のアーキテクチャが特徴です。このモデルは、エンコーダとデコーダから成り立っており、エンコーダで特徴を抽出し、デコーダで画像の解像度を復元しながらセグメンテーションのマップを生成します。スキップ接続を用いることで、異なる解像度の特徴情報を統合し、詳細なセグメンテーションを実現しています。
Mask R-CNNは、物体検出とセマンティックセグメンテーションを同時に行うためのモデルです。Fast R-CNNやFaster R-CNNといった物体検出のフレームワークをベースに、物体のマスク生成のためのブランチを追加しています。これにより、画像内の物体の境界をピクセルレベルで正確に抽出することが可能となっています。
YOLO(You Only Look Once)は、その名の通り、画像を一度だけ見ることで物体の検出を行うモデルです。従来のモデルとは異なり、一度の推論で全ての物体の位置とクラスを同時に予測するため、高速な検出が可能です。
これらの技術については、別の機会に改めて詳しく説明したいと思います。
■生成モデルの進化(GANs)
Generative Adversarial Networks (GANs) は、近年のディープラーニングの分野で注目を集める技術の一つとなっています。GANは、2014年にIan Goodfellowらによって初めて紹介されました。このモデルは、生成器(Generator)と識別器(Discriminator)という二つのネットワークを競わせることで、高品質な合成画像を生成する能力を持ちます。
生成器は、ランダムなノイズから画像を生成することを目指し、識別器は、生成された画像が本物の画像か、生成器によって生成された偽物の画像かを判定します。この相互の競争によって、生成器は次第によりリアルな画像を生成する能力を獲得していきます。
StyleGANは、スタイル変換と多様な特徴を制御するための構造を導入しました。これにより、非常に高解像度で詳細な画像を生成することができるようになりました。また、BigGANは、大規模なデータセットと巨大なモデルサイズを用いて、前例のないクオリティと解像度の画像を生成する能力を持っています。
これらの技術についても、別の機会に改めて詳しく説明したいと思います。
■自己教師あり学習(Self-supervised learning)
この学習手法の主要な魅力は、大量のラベル付きデータを必要とせずに、データ自体から有用な特徴を学習する能力にあります。
ラベル付きデータの収集やアノテーションは、多くの場合、時間とコストがかかるため、それを回避できる自己教師あり学習は非常に魅力的です。この手法では、データに対して何らかのタスク(予測、再構築など)を定義し、そのタスクを解くことで、データの構造やパターンを捉える特徴を学習します。
Contrastive learningは、自己教師あり学習の中でも特に注目される手法の一つです。このアプローチでは、データの異なる変換や変種(augmentation)間での類似性を強化しながら、異なるデータサンプル間の類似性を低減することを目的としています。この相対的な比較によって、ネットワークはデータの重要な特徴を効果的に捉えることができます。
SimCLR(Simple Contrastive Learning of Visual Representations)は、Contrastive learningを用いた具体的な手法の一つで、データ拡張と特徴空間での正規化を組み合わせることで、高品質な特徴表現を学習します。
このように、深層学習の発展は、新しいネットワーク構造の提案や、新しい学習手法の導入、特定のタスクへの特化など、多岐にわたる進化を遂げてきました。
Break>>
画像における深層学習では、畳み込みという言葉が出てきます。畳み込みとはどのような操作なのでしょうか?
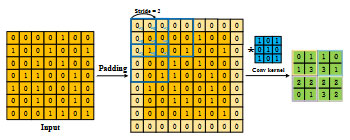
図 6は、実際に畳み込み処理を行っている例です。最終的に出力されている緑の左上の4つを例として計算してみましょう(図中の「padding」と「stride」という二つの概念は、畳み込み操作の出力のサイズや、フィルタ(またはカーネル)が入力データにどのように適用されるかを制御するための重要なものですが、説明は割愛します。どのような概念かは、ご自身で調べてみてください)。
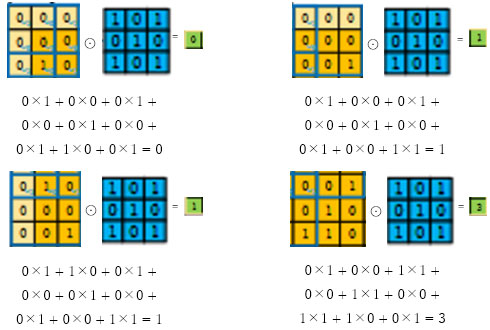
(ここで、⊙はアダマール積といいます)
図 7のように、特定のフィルタ(またはカーネル:青色)を画像上でスライドさせながら、そのフィルタ内の値と画像の各ピクセルの値との積の合計を計算することで新しい画像を生成することができます。
畳み込み自体の概念は古く、数学や工学の多くの分野で長い間使用されてきました。代表的なものに、画像処理や、音声処理があります。画像処理では、画像の平滑化、エッジ検出、特徴抽出などの多くの画像処理に使用され、地形解析においてもよく使用されるフィルタ手法の一つです。また、音声処理では、エコーキャンセレーションやリバーブの生成など、音声や音楽の処理に使用されていました。しかし、畳み込みを使用したニューラルネットワーク、すなわちCNNのアイデアは、1980年代にYann LeCunらによって導入されました。彼らは「LeNet-5」という初の成功した畳み込みニューラルネットワークを開発し、手書きの数字の認識タスクで高い性能を達成しました。この成功は、CNNの可能性を示すものであり、後の深層学習のブームへの礎となりました。
第7回は、深層学習(言語系)を取り上げます。今、世間をにぎわせている言語モデルについて、画像系と同じように時系列にそって説明していきます。
参考資料
1)Stanford Vision Labより「GradientBased Learning Applied to Document Recognition」
2)NeurIPS より「ImageNet Classification with Deep Convolutional Neural Networks」
3)プリプリントタイトル「Going deeper with convolutions」
4)プリプリントタイトル「U-Net: Convolutional Networks for Biomedical Image Segmentation」
(図中conv: convolution, ReLU: 活性化関数, max pool: max pooling, up-conv: up convolution)
5)プリプリントタイトル「A Survey of Convolutional Neural Networks:Analysis, Applications, and Prospects」
※上記コラム内のWebサイトの最終参照日は2023年9月