技術資料
Feel&Think
第5回 機械学習(教師無し学習)
前回の「機械学習(教師あり学習)」では、教師あり学習に使用されるアリゴリズムについて説明し、また、現在話題となっているGPTについて基本となっているアルゴリズムを紹介しました。
今回の第5回では、「機械学習(教師無し学習)」のアルゴリズムについて説明します。今回は、jupyter-notebook形式のソースコードのリンクを各アルゴリズムの終わりに貼っています。「>>参考ソースコード」をクリックするとGoogle Collaboratory*が起動し、実行が可能になりますので、是非ご自身で確認してみて下さい。
*Google Collaboratory使用には、googleアカウントが必要になります
■クラスタリング(Clustering)
似たようなデータをグループにまとめる手法で、顧客セグメンテーションや画像のセグメンテーションなどに使用されます。アルゴリズム例を以下に示します。
- k平均法(k-means clustering)
- 階層的クラスタリング
■k平均法(k-means clustering)
非階層型のクラスタリング手法であり、データセットをk個のクラスに分類するものです。この方法は、データの中でk個のクラスタ中心を計算し、各データ点を最も近いクラスタ中心に割り当てることで機能します。
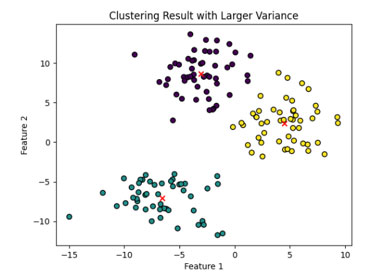
(クラスタの中心点は赤い「x」マークで示されています)
同様な手法として、混合ガウスモデル(Gaussian Mixture Model, GMM)があります。この手法は、データが複数のガウス分布から生成されると仮定するクラスタリング手法です。k平均法と比較して、クラスタの形がより柔軟にモデル化できる利点があります。
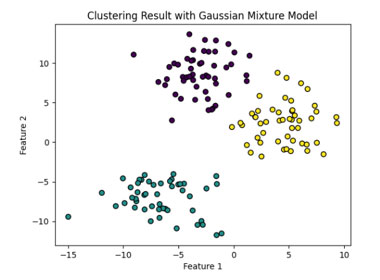
GMMは、クラスタ内のデータの分布に対してより柔軟なモデリングが可能であるため、k平均法では適切にクラスタリングできないようなデータに対しても効果的に動作することがあります。一方で、計算量が多く、最適化が難しい場合もあるため、適用するデータとタスクに応じて慎重な選定と設定が求められます。以下に5個のクラスタの例を示します。
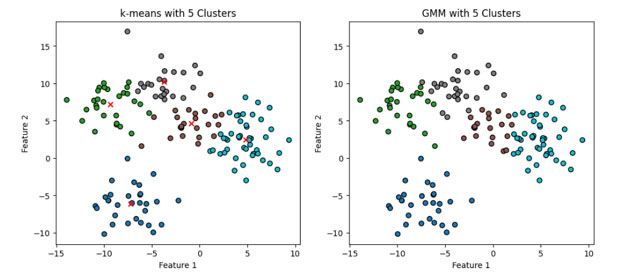
>>参考ソースコード
■階層的クラスタリング
データの類似性に基づいてクラスタを形成する手法です。この手法では、最初に各データポイントを個別のクラスタとして扱い、次に類似性が最も高いクラスタ同士を結合して新しいクラスタを作ります。このプロセスを繰り返し、全データポイントが一つのクラスタに結合されるまで続けます。クラスタ間の類似性を測る方法には様々な距離尺度が使われることがあります。例えば、最短距離法、最長距離法、平均距離法などが挙げられます。結果はデンドログラムと呼ばれる木構造の図で表されることが多く、この図を用いてクラスタの数や構造を解釈します。
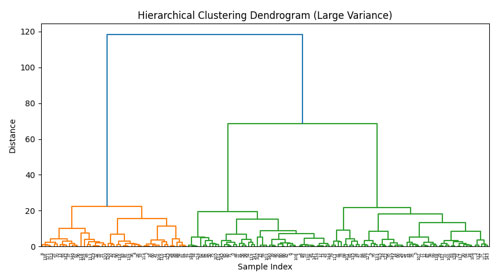
このデータを6つのクラスタに分けた場合以下のようになります。
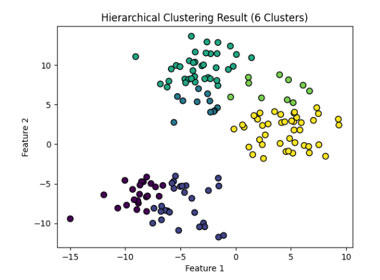
階層的クラスタリングはデータの構造を探索するのに役立つため、市場分析、生物学的データ解析など、多岐にわたる分野で利用されています。
■次元圧縮(Dimensionality Reduction)
データの次元を削減し、情報を圧縮する手法で、次元削減により、データの可視化や処理速度の向上が期待できます。アルゴリズム例を以下に示します。
- 主成分分析(PCA, Principal Component Algorithm)
- t-SNE(t-distributed Stochastic Neighbor Embedding)
■主成分分析(PCA, Principal Component Algorithm)
主成分分析(PCA)は、多変量データの次元削減手法の一つです。データセットの主要な変動を捉える方向を見つけるために用いられます。具体的には、データの共分散行列を計算し、その固有ベクトルと固有値を求めます。最も大きな固有値に対応する固有ベクトルが、データの主成分で、その方向にデータを射影することで次元削減が行われます。PCAはデータの圧縮や可視化に有用であり、ノイズの除去や他の機械学習手法への前処理としても使われます。
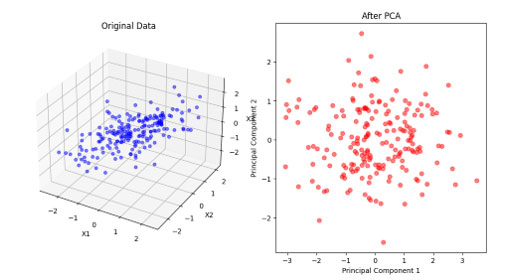
上図は、左側が元の3次元データ、右側が主成分分析(PCA)によって2次元に削減されたデータを示しています。左側の3次元データには2つの主要な方向があり、PCAによってそれらの方向を捉え、2次元に削減しました。右側の図では、この2次元データが主要な方向を保存していることが分かります。このようにPCAは、データの構造を理解しやすくするための強力なツールであり、多くの分野で広く使用されています。
■t-SNE(t-distributed Stochastic Neighbor Embedding)
t-SNEは、高次元データを低次元空間(通常は2Dまたは3D)にマッピングするための機械学習アルゴリズムです。この技法は、特に高次元データの視覚化に適しており、データポイント間の相対的な距離を低次元空間で保存しようとします。
t-SNEの基本的なアイデアは、各データポイントを高次元空間と低次元空間の両方で確率的に近隣の点としてモデル化し、これらの確率分布ができるだけ類似するように低次元の表現を最適化することです。
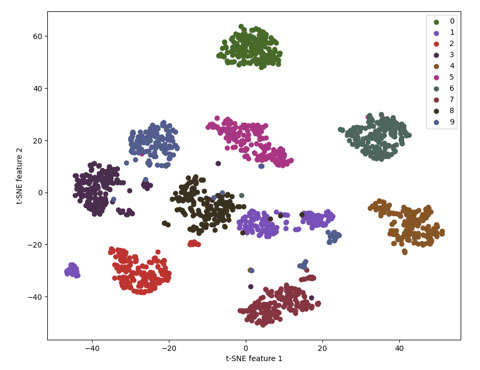
上図は、MNISTデータセットの手書き数字をt-SNEを使用して2次元にマッピングした結果を示しています。各色は異なる数字(0から9)を表しており、t-SNEの強力さが確認できます。すなわち、数字ごとにクラスタが形成され、異なる数字のクラスタが互いに離れていることがわかります。これにより、手書きの数字がどれほど互いに似ているか、また異なっているかを視覚的に理解することができます。
■異常検知(Anomaly Detection)
正常なデータのパターンを学習し、異常なデータを検出する手法です。アルゴリズム例を以下に示します。
- One-Class SVM
- Isolation Forest
■One-Class SVM
One-Class SVM(サポートベクターマシン)は、異常検知に主に使用されるアルゴリズムです。通常のSVMが2つのクラス間の境界を学習するのに対し、One-Class SVMはデータセットの「正常」な部分のみから学習します。このアプローチは、異常値が少なく、ラベル付けが困難な場合に特に有用です。
One-Class SVMは、データの分布を囲むように高次元空間におけるハイパープレーンを構築します。新しいデータポイントがこのハイパープレーンの「内側」にあるか「外側」にあるかを判断することで、異常を検出します。カーネルトリックを使用することで、非線形な境界も描画できます。
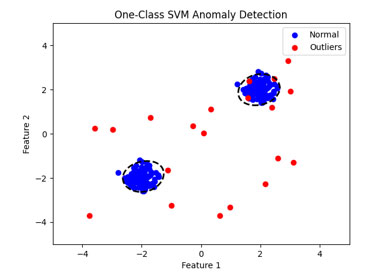
上図では、One-Class SVMによる異常検知が可視化されています。青い点は正常なデータを表し、赤い点は異常なデータを表しています。黒い線はOne-Class SVMによって学習された境界であり、この線の外側にあるデータポイントは異常と判断されます。
■Isolation Forest
Isolation Forest(アイソレーションフォレスト)は、異常検知のためのアルゴリズムの一つです。このアルゴリズムの主要なアイデアは、異常なデータポイントは正常なデータポイントよりも簡単に「孤立」できるというものです。したがって、少数のスプリットでデータを孤立させることができれば、そのデータは異常と見なされる可能性が高いです。
Isolation Forestは高い計算効率を持ちながらも、多次元データにおける異常を効果的に検出することができます。
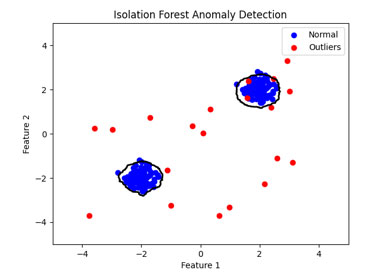
上図は、Isolation Forestによる異常検知の結果を示しています。青い点は正常なデータを表し、赤い点は異常なデータを表しています。黒い線はIsolation Forestが計算した異常スコアの閾値に基づいて描かれており、この線の外側にあるデータポイントは高い異常スコアを持ち、異常と判断されます。
■自己符号化器(Autoencoders)
ニューラルネットワークを用いた次元削減やデータ再構成の手法で、ノイズ除去などにも用いられます。アルゴリズム例を以下に示します。
- 単純な自己符号化器(AE)
- 変分自己符号化器(VAE)
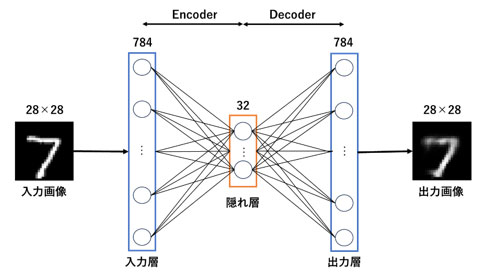
■単純な自己符号化器(AE)
自己符号化器は、ニューラルネットワークを使用して入力データを圧縮して再構築する非監督学習の一形態です。主に2つの部分から成り立っています:エンコーダとデコーダです。エンコーダは入力データを低次元の潜在空間にマッピングします。デコーダはこの潜在表現を取り、元のデータの再構築を試みます。訓練中、自己符号化器は入力として与えられたデータを再構築する方法を学びます。そのため、損失関数は再構築エラー(入力と出力の間の差異)を最小化します。自己符号化器はノイズ除去、特徴抽出、次元削減などのタスクに使用されます。
単純な自己符号化器を構築してMNISTデータセットを使って訓練します(下図)。
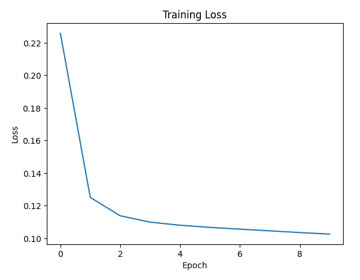
上図のように訓練の過程で、自己符号化器は再構築誤差を減少させるように学習しています。プロットから、損失が徐々に減少していることが確認できます。
次に、テストデータを使用してモデルの再構築の品質を評価し、元の画像と再構築された画像を比較します。

■変分自己符号化器(VAE)
変分自己符号化器(VAE)は、ディープラーニングを用いた生成モデルの一つであり、データの高次元な表現を低次元の潜在空間に圧縮することを目指します。VAEは、潜在空間の点からデータを生成することも可能です。VAEの特徴的な点は、潜在変数の事後分布を推論することであり、これは変分推論を用いて行われます。
具体的には、エンコーダがデータを潜在空間の確率分布に変換し、デコーダがこの潜在空間から元のデータ空間に変換を行います。学習の際には、再構築誤差とKLダイバージェンスという2つの損失を最小化するように最適化が行われます。この構造により、VAEは入力データと似た新しいデータを生成する能力を持ちます。
要するに、先に述べたAEとの違いとして、VAEはAEの拡張版として、データの生成や潜在空間の確率的な探索が可能なモデルとなっています。

上図のように潜在変数2次元にして、デコーダから得られた画像を並べると、数字が連続的に変化していく様子が見て取れます。
そのほかにも、データの特徴を捉え、低次元空間にマッピングするニューラルネットワークの一種である「自己組織化マップ(Self-Organizing Maps)」や、密度ベースのクラスタリングアルゴリズムである「DBSCAN (Density-Based Spatial Clustering of Applications with Noise)」など多くのアルゴリズムが存在します。是非これを機会に調べてみてはどうでしょうか?
第6回は、いよいよ深層学習(画像系)について説明します。